

Java Jsoup Tutorial
Java Jsoup tutorial is a powerful Java library for extracting and manipulating data from websites using HTML5 DOM methods and CSS selectors. This library is designed to scrape and parse HTML from a URL, but it can also find and extract data through DOM traversal or CSS selectors. It is also capable of manipulating HTML elements, attributes, and text. To avoid XSS attacks, it can also clean the content submitted by user.
You may use this Java Library to develop your own Java application to scrape data from a URL, and if you want to learn more Java programming tutorials, you can go here to check out other programming tutorials. In this Jsoup tutorial, I will demonstrate how to use this Library or API (Application Programming Interface).
Jsoup Tutorial Java
In this Jsoup Tutorial Java, You will learn how to download and integrate the Java library into your Java program. If you are using Java Ant, Maven, or Java Gradle, please continue reading to learn how to download the library. Let’s start with Java Ant and then go on to Maven and Gradle.
Jsoup Ant
If you are using Jsoup Ant, you will need to download the jar file (core library). After you have downloaded the jar file, you must place it in your project library or the global library. To include the jar file into your project, go to the Libraries section and add the jar file. There is another method to add the jar file; try it if you don’t want to locate the jar file every time you use it. Follow the steps below if you are using NetBeans.
- Go to Tools
- Click on Libraries
- Click on New Library and enter the Library name
- Add the Jar at the Classpath tab
That’s how you add the jar file to your NetBeans IDE’s global Libraries.
Jsoup Maven
If you want to use Jsoup Maven, you do not need to download the jar file. Simply insert the dependencies into your Java project, insert the following code into your POM’s <dependencies> section. Simply go to jsoup.org if you don’t know the latest version of the library.
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.14.3</version> </dependency>
Gradle
Add the following code, if you are using Java Gradle.
implementation 'org.jsoup:jsoup:1.14.3'
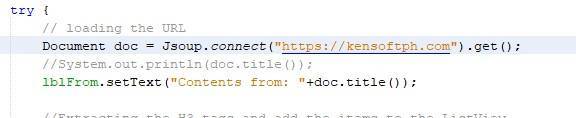
We can use this code below to see if the code is successfully linked to the specified website. The code example below will tell you if we successfully loaded the website.
Document doc = Jsoup.connect("https://kensoftph.com").get();
System.out.println(doc.title());
The output will be the Title of the specified website.
Jsoup Example
In this Jsoup example, I will show a few examples of how to use this Java Library. I know you want to learn more about this library, so go to jsoup.org and navigate to Cookbook. The coverage in the following example will be loading the specified website and extracting some of the specified website’s HTML elements. It is commonly known as web scraping program using Java. Continue reading to learn more.
Example: Load a Document from a URL
Loading a document from a URL is quite simple and straightforward, as seen above. If you haven’t read the entire tutorial, please proceed below to learn how to load a document from a URL.
Document doc = Jsoup.connect("https://kensoftph.com").get();
System.out.println(doc.title());
Output
Kensoft PH
Example: Data extraction from a document
This example demonstrates how to extract data from a document. Extracting data from a document is a little hard, but if you follow the example, it will be much easy. To learn more, I recommend visiting jsoup.org’s Cookbook page.
import java.io.IOException;
import java.net.URL;
import java.util.ResourceBundle;
import java.util.logging.Level;
import java.util.logging.Logger;
import javafx.fxml.FXML;
import javafx.fxml.Initializable;
import javafx.scene.control.Label;
import javafx.scene.control.ListView;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* FXML Controller class
*
* @author KENSOFT
*/
public class FX_ScraperController implements Initializable {
@FXML
private Label lblFrom;
@FXML
private ListView<String> listView;
@FXML
private Label lblSelectedItem;
/**
* Initializes the controller class.
*/
@Override
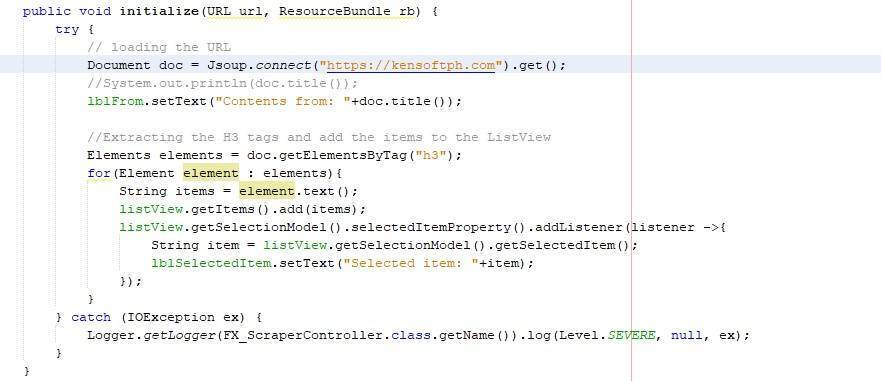
public void initialize(URL url, ResourceBundle rb) {
try {
// loading the URL
Document doc = Jsoup.connect("https://kensoftph.com").get();
//System.out.println(doc.title());
lblFrom.setText("Contents from: "+doc.title());
//Extracting the H3 tags and add the items to the ListView
Elements elements = doc.getElementsByTag("h3");
for(Element element : elements){
String items = element.text();
listView.getItems().add(items);
listView.getSelectionModel().selectedItemProperty().addListener(listener ->{
String item = listView.getSelectionModel().getSelectedItem();
lblSelectedItem.setText("Selected item: "+item);
});
}
} catch (IOException ex) {
Logger.getLogger(FX_ScraperController.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
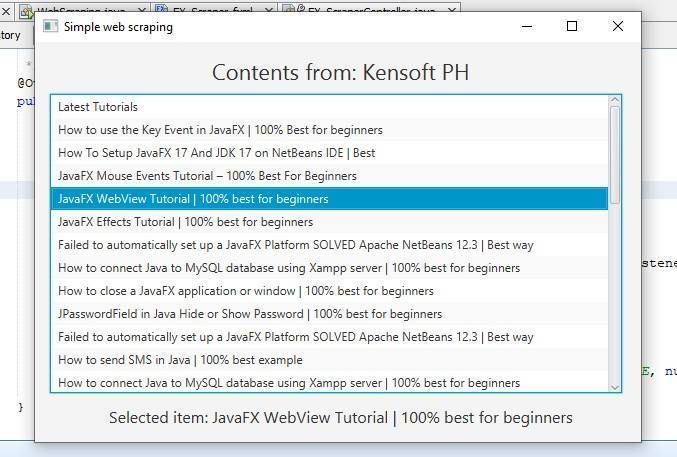
Output
This is the output of extracting a data from an HTML document loaded from a URL.
If you wish to download the JavaFX Project of the Simple Web Scraping application. I’ve provided a download link below so you can quickly get started and tweak it yourself. If you like my tutorials, don’t hesitate to click here or watch my YouTube Video below to learn more via video based in this article.
YouTube Video













Thanks bro!!!
Glad it was helpful